是人工智慧(AI)分支,讓電腦系統能夠從資料中學習,並根據經驗改進,而不是按照明確的程式碼運行作業。機器學習演算法會分析大量資料,尋找資料中的模式和規律,並利用這些模式和規律對未知資料進行預測或分類
圖片來源:Demystifying Machine Learning: An In-depth Exploration of Concepts and Applications
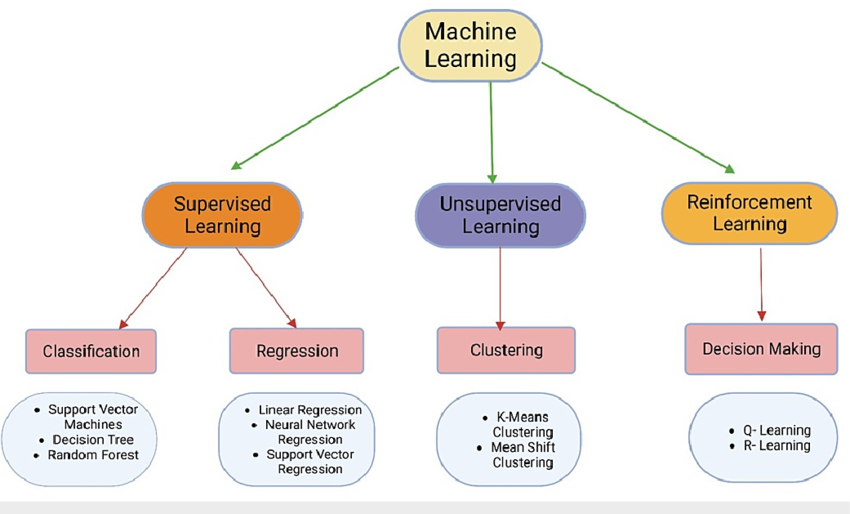
監督式學習(Supervised learning):在監督式學習中,資料會被標記上正確答案或類別。機器學習演算法會學習這些標記映射關係,並利用這些映射關係對未知資料進行預測或分類。監督式學習常見任務包括 分類(Classification)、 迴歸(Regression)

非監督式學習(Un-supervised learning):在非監督式學習中,資料沒有任何標記。機器學習演算法需要從未標記的資料中發現資料內在結構或模式。非監督式學習常見任務包括 聚類(Clustering)、降維(Dimensionality reduction)
半監督式學習(Semi-supervised learning):在半監督式學習中,資料部分被標記,部分未標記。機器學習演算法會利用標記資料和未標記資料來學習資料的映射關係或內在結構。半監督式學習常見任務包括 分類、聚類
強化學習(Reinforcement learning):在強化學習中,代理(Agent) 會與環境互動,並在互動過程中從環境中獲得獎勵或懲罰。代理會根據獎勵或懲罰來調整自己的行為策略,以最大化累計獎勵。強化學習常見任務包括 機器人控制、遊戲程式設計
自動化決策:能夠從大量數據中學習規律,並自動做出決策,減少人工干預,提高效率提高準確性:相較於傳統規則引擎,機器學習模型能夠處理更複雜數據,並獲得更高準確性發現新知識:可以從數據中發現人類難以發現模式和關係,為科學研究和商業應用提供新的洞見個性化服務:可以根據用戶的行為和偏好,提供個性化服務和推薦適應性強:能夠隨著數據量增加和數據分佈變化,不斷地自我調整和優化持續學習:可以通過不斷地學習新數據,來提高自身性能和適應環境變化數據依賴: 機器學習模型性能高度依賴於數據的質量和數量。如果數據存在偏差或噪聲,模型的預測結果就會受到影響模型複雜性: 許多機器學習模型結構非常複雜,這使得模型訓練和調參變得困難,需要專業的知識和經驗可解釋性差: 一些機器學習模型,例如:深度學習模型,具有很強學習能力,但決策過程往往是一個「黑盒子」,難以解釋模型是如何做出決策的,在一些對模型可解釋性要求高應用場景中是一個挑戰計算資源消耗大: 特别是深度學習模型,訓練過程需要大量計算資源,例如:GPU、TPU
過度擬合: 模型過於複雜,導致其對訓練數據過度擬合,在測試數據上的表現較差偏見問題: 如果訓練數據存在偏見,模型也會學習到這些偏見,導致不公平的結果隱私問題: 機器學習模型訓練需要大量數據,這可能涉及到用戶隱私問題,需要採取適當的措施來保護數據安全需要專業知識: 建構和部署機器學習模型需要一定專業知識,包括 數據科學、統計學、程式設計
電腦視覺(Computer vision):識別圖像和影片中的物體、人臉、場景自然語言處理(Natural language processing):理解和生成人類語言語音識別(Speech recognition):將語音轉換為文字機器翻譯(Machine translation):將一種語言的文字翻譯成另一種語言推薦系統(Recommendation system):向使用者推薦商品、電影、音樂import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 載入數據
data = pd.read_csv('data.csv')
# 分割數據集
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 建立模型
model = LinearRegression()
# 訓練模型
model.fit(X_train, y_train)
# 評估模型
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('Mean Squared Error:', mse)
隨著資料量增長和計算能力提高,機器學習將在未來發揮更加重要作用。也將能夠解決更加複雜的問題,並在更多領域得到應用


 iThome鐵人賽
iThome鐵人賽